
Postgres is the best relational database system. This is law. One of the reasons for this is due to how easily it works with the JSON format. If I'm working with SQL, I'm probably also working with Javascript and Javascript is married to JSON. I am going to go over the built in functions in PSQL that allow queries to return data in json format instead of clunky rows and columns. I used these functions extensively in 2021 and I recommend back end developers check this out.
Turning relational data into JSON
Below are some examples of how to return data in different formats using built-in Postgres functions. I can neither confirm nor deny that this is here for my reference.
Convert multiple rows and columns into an array with an object per row with a key for each columns.
SQL:
select
array_to_json(array_agg(row_to_json(product))) as result
from product
Output:
[
{
"name":"name1",
"description":"description1"
},
{
"name":"name2",
"description":"description2"
},
{
"name":"name3",
"description":"description3"
}
]
Convert a single row into an object with a key for each column without wrapping it in an array:
SQL:
select
row_to_json(product) as result
from product
Output:
{
"name":"name1",
"description":"description1"
}
Build an object with a key for each value in one column paired with a value for each value in another column:
SQL:
select
json_object_agg(name, description) as obj
from product
Output:
{
"name1":"description1",
"name2":"description2",
"name3":"description3"
}
Build an array containing all of the values from a single column:
SQL:
select
array_to_json(array_agg(name)) as obj
from product
Output:
[
"name1",
"name2",
"name3"
]
Build an object with a key for each value in one column where the value is an object built from multiple columns:
SQL:
select
json_object_agg(id, json_build_object('name',name,'description',description)) as obj
from product
Output:
{
"1":{
"name":"name1",
"description":"description1"
},
"2":{
"name":"name2",
"description":"description2"
},
"3":{
"name":"name3",
"description":"description3"
}
}
Aren't they beautiful?
A lot of the time when I use these, I'm building complex objects and using common table expressions. So my query might end up looking something like this:
SQL:
with myactualquery as (
-- query that returns columns and rows (ew!) here
)--select * from myactualquery;
select
array_to_json(array_agg(row_to_json(myactualquery))) as result
from myactualquery;
Output:
It terms of maintenance, i.e. the difficulty of coming back to this to make changes, it should be about the same as writing query building code. It just requires a different knowledge set. The great thing about chaining queries together with CTEs is that you can leave commented out selects as seen above. That makes it fast to troubleshoot every step of a query.
Putting JSON back into into the database
On rare occassion, I have written queries that take in json formatted input and process it from there to insert or update records.
The boilerplate for that looks something like this:
with processedinput as (
select
value->>'description' as desctext,
(value->>'quantity')::int as quantitynum
from json_array_elements('[{"description":"item1","quantity":2},{"description":"item2","quantity":3}]'::json)
)select * from processedinput;
,
update ...
Output:
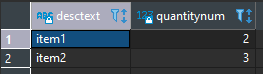
The json string can be replaced with a $1 or %s as needed. This selects each element in a json array and extacts values into columns. Now you have your data in a table for SQL to play with. Note that when accessing a property of a json object with ->>, the returned type is text. You might want to typecast some columns as I did with an int quantity property above.
If for some reason, you want to take in multiple inputs of different types at the same time, you might break it up into something like this:
with allmyinputs as (
select
'[{"description":"item1","quantity":2},{"description":"item2","quantity":3}]'::json as mydata,
2 as myotherinput
)
,--select * from allmyinputs;
processedinput as (
select
value->>'description' as desctext,
(value->>'quantity')::int as quantitynum
from allmyinputs
cross join json_array_elements(allmyinputs.mydata)
)select * from processedinput;
,
update ...
This is where it gets a bit messy. At first glance, that cross join looks like a disaster, but it just builds a value column containing a json object in every row. The reason for this pattern is to have all inputs in a query at the top rather than scattered throughout. This helps a lot when you are comparing a query to the code calling it, trying to see how the inputs line up. It also comes in handy when you have to restruct a query in a way that would have forced you to reorder the inputs, which forces you to change every place where the query was ever called.
Why I like this functionality so much
router.route("/getuserdata").post((req: Request, res: Response, next: NextFunction) => {
if (!req.isAuthenticated()) {
return res.status(401).json({ success: false, errmessage: "You are not logged in." });
}
queryPsqlJson("getuserdata", [req.user.email_address], (error: Error, result: any) => {
if (error) {
logger.info("error getting user data");
logger.info(error.message);
return res.status(500).send();
}
return res.status(200).json({ success: true, data: result });
});
});
Above is a basic Node.js api endpoint from my latest project. It calls a function that takes in a query name and parameters and its callback returns the object found in the first row and column of the query result. Pretty much all this API does is run a query and send it back to the user. There's also some authentication and error handling, but this endpoint is dead simple and it doesn't even care what the data looks like. Between this route and the query, there's only about fifty lines of code to hand the client a complex set of data belonging to a logged in user. Pog.
Why not use an ORM?
I have shifted away from ORMs in the last few years. I maintained Swing in Enterprise Java for awhile and that was rough. Later on when I was implementing new features, I was writing SQL instead. Once I learned SQL, I found it easier to write and maintain. Yes, most ORMs are better than Swing. But I have worked with Java, PHP and Node which all have their own distinct ORMs to learn. Rather than learning new ORMs every time, you only really have to learn SQL once.
ORMs like to sell themselves on how much easier a migration to a new database system will be, but they make it equally more difficult to migrate to a different back end. You will probably switch ORMs four or more times in your career before SQL becomes obsolete. This makes learning SQL efficient in terms of how much you get out of it for the time spent learning it.
Once I learned SQL, I have found it faster to get a new project off the ground without bringing in an ORM since they add extra work to get going. The only benefit would be if I genuinely believed that I would migrate away from Psql sooner than I migrated away from Node.js, or would end up working with developers who don't know SQL. I don't foresee either of those situations.